 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Remote Inference from Unreliable Components: Joint Communication and Computation Limits
Apr 21, 2026Classical information theory typically assumes reliable receiver-side processing. We study remote inference when communication is noisy and the receiver itself is built from unreliable components under a finite redundancy budget. Under a committed/no-bypass receiver closure, task-relevant information can affect the final estimate only by passing through a budgeted collection of vulnerable primitives unless an explicit protected bypass is modeled. Modeling each vulnerable primitive as a memoryless noisy channel yields a baseline supply--demand converse: the task-relevant information needed to attain a target distortion cannot exceed the smaller of the total information supplied by the communication channel and the total information supplied by the vulnerable compute budget. Our main converse shows that committed intermediate interfaces create additional first-order serial cuts and receiver-internal computation-graph cuts, captured in general by a receiver-internal compute min-cut converse. In particular, the twofold loss in the symmetric two-stage hard-separation special case is not inherent to unreliable receiver computation but induced by hard-separation under the committed/no-bypass closure. This extra first-order tax is therefore closure-dependent rather than universal. On the converse side, if downstream modules retain soft visibility to the raw channel output, the converse reduces to the single-bottleneck supply, up to any explicitly reserved soft-path budget. Under a separate stronger protected-support closure with reliable decoder and control support, we establish achievability results for task-direct and serial hard-separation constructions. For the fully noisy-logic regime, we obtain only a conservative depth-dependent converse, and matched achievability remains open.
ZoomSpec: A Physics-Guided Coarse-to-Fine Framework for Wideband Spectrum Sensing
Apr 15, 2026Wideband spectrum sensing for low-altitude monitoring is critical yet challenging due to heterogeneous protocols,large bandwidths, and non-stationary SNR. Existing data-driven approaches treat spectrograms as natural images,suffering from domain mismatch: they neglect time-frequency resolution constraints and spectral leakage, leading topoor narrowband visibility. This paper proposes ZoomSpec, a physics-guided coarse-to-fine framework integrating signal processing priors with deep learning. We introduce a Log-Space STFT (LS-STFT) to overcome the geometric bottleneck of linear spectrograms, sharpening narrowband structures while maintaining constant relative resolution. A lightweight Coarse Proposal Net (CPN) rapidly screens the full band. To bridge coarse detection and fine recognition, we design an Adaptive Heterodyne Low-Pass (AHLP) module that executes center-frequency aligning, bandwidth-matched filtering, and safe decimation, purifying signals of out-of-band interference. A Fine Recognition Net (FRN) fuses purified time-domain I/Q with spectral magnitude via dual-domain attention to jointly refine temporal boundaries and modulation classification. Evaluations on the SpaceNet real-world dataset demonstrate state-of-the-art 78.1 mAP@0.5:0.95, surpassing existing leaderboard systems with superior stability across diverse modulation bandwidths.
Evolving Prompt Adaptation for Vision-Language Models
Mar 10, 2026The adaptation of large-scale vision-language models (VLMs) to downstream tasks with limited labeled data remains a significant challenge. While parameter-efficient prompt learning methods offer a promising path, they often suffer from catastrophic forgetting of pre-trained knowledge. Toward addressing this limitation, our work is grounded in the insight that governing the evolutionary path of prompts is essential for forgetting-free adaptation. To this end, we propose EvoPrompt, a novel framework designed to explicitly steer the prompt trajectory for stable, knowledge-preserving fine-tuning. Specifically, our approach employs a Modality-Shared Prompt Projector (MPP) to generate hierarchical prompts from a unified embedding space. Critically, an evolutionary training strategy decouples low-rank updates into directional and magnitude components, preserving early-learned semantic directions while only adapting their magnitude, thus enabling prompts to evolve without discarding foundational knowledge. This process is further stabilized by Feature Geometric Regularization (FGR), which enforces feature decorrelation to prevent representation collapse. Extensive experiments demonstrate that EvoPrompt achieves state-of-the-art performance in few-shot learning while robustly preserving the original zero-shot capabilities of pre-trained VLMs.
Lang2Str: Two-Stage Crystal Structure Generation with LLMs and Continuous Flow Models
Mar 04, 2026Generative models hold great promise for accelerating material discovery but are often limited by their inflexible single-stage generative process in designing valid and diverse materials. To address this, we propose a two-stage generative framework, Lang2Str, that combines the strengths of large language models (LLMs) and flow-based models for flexible and precise material generation. Our method frames the generative process as a conditional generative task, where an LLM provides high-level conditions by generating descriptions of material unit cells' geometric layouts and properties. These descriptions, informed by the LLM's extensive background knowledge, ensure reasonable structure designs. A conditioned flow model then decodes these textual conditions into precise continuous coordinates and unit cell parameters. This staged approach combines the structured reasoning of LLMs and the distribution modeling capabilities of flow models. Experimental results show that our method achieves competitive performance on \textit{ab initio} material generation and crystal structure prediction tasks, with generated structures exhibiting closer alignment to ground truth in both geometry and energy levels, surpassing state-of-the-art models. The flexibility and modularity of our framework further enable fine-grained control over the generation process, potentially leading to more efficient and customizable material design.
SDCM: Simulated Densifying and Compensatory Modeling Fusion for Radar-Vision 3-D Object Detection in Internet of Vehicles
Jan 29, 20263-D object detection based on 4-D radar-vision is an important part in Internet of Vehicles (IoV). However, there are two challenges which need to be faced. First, the 4-D radar point clouds are sparse, leading to poor 3-D representation. Second, vision datas exhibit representation degradation under low-light, long distance detection and dense occlusion scenes, which provides unreliable texture information during fusion stage. To address these issues, a framework named SDCM is proposed, which contains Simulated Densifying and Compensatory Modeling Fusion for radar-vision 3-D object detection in IoV. Firstly, considering point generation based on Gaussian simulation of key points obtained from 3-D Kernel Density Estimation (3-D KDE), and outline generation based on curvature simulation, Simulated Densifying (SimDen) module is designed to generate dense radar point clouds. Secondly, considering that radar data could provide more real time information than vision data, due to the all-weather property of 4-D radar. Radar Compensatory Mapping (RCM) module is designed to reduce the affects of vision datas' representation degradation. Thirdly, considering that feature tensor difference values contain the effective information of every modality, which could be extracted and modeled for heterogeneity reduction and modalities interaction, Mamba Modeling Interactive Fusion (MMIF) module is designed for reducing heterogeneous and achieving interactive Fusion. Experiment results on the VoD, TJ4DRadSet and Astyx HiRes 2019 dataset show that SDCM achieves best performance with lower parameter quantity and faster inference speed. Our code will be available.
Bandwidth-Efficient Adaptive Mixture-of-Experts via Low-Rank Compensation
Dec 18, 2025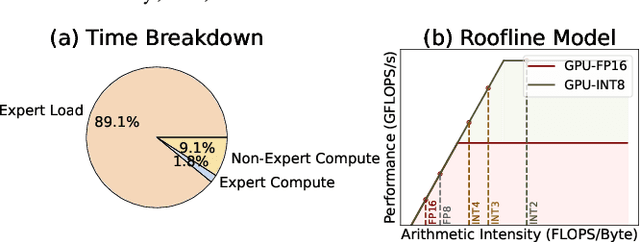

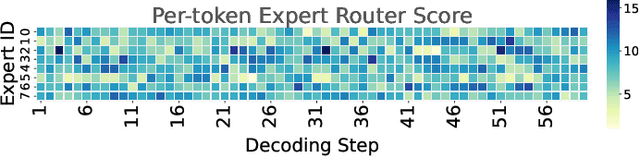
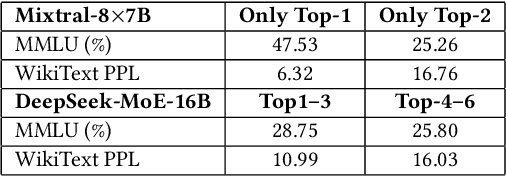
Mixture-of-Experts (MoE) models scale capacity via sparse activation but stress memory and bandwidth. Offloading alleviates GPU memory by fetching experts on demand, yet token-level routing causes irregular transfers that make inference I/O-bound. Static uniform quantization reduces traffic but degrades accuracy under aggressive compression by ignoring expert heterogeneity. We present Bandwidth-Efficient Adaptive Mixture-of-Experts via Low-Rank Compensation, which performs router-guided precision restoration using precomputed low-rank compensators. At inference time, our method transfers compact low-rank factors with Top-n (n<k) experts per token and applies compensation to them, keeping others low-bit. Integrated with offloading on GPU and GPU-NDP systems, our method delivers a superior bandwidth-accuracy trade-off and improved throughput.
Topology-Agnostic Animal Motion Generation from Text Prompt
Dec 11, 2025Motion generation is fundamental to computer animation and widely used across entertainment, robotics, and virtual environments. While recent methods achieve impressive results, most rely on fixed skeletal templates, which prevent them from generalizing to skeletons with different or perturbed topologies. We address the core limitation of current motion generation methods - the combined lack of large-scale heterogeneous animal motion data and unified generative frameworks capable of jointly modeling arbitrary skeletal topologies and textual conditions. To this end, we introduce OmniZoo, a large-scale animal motion dataset spanning 140 species and 32,979 sequences, enriched with multimodal annotations. Building on OmniZoo, we propose a generalized autoregressive motion generation framework capable of producing text-driven motions for arbitrary skeletal topologies. Central to our model is a Topology-aware Skeleton Embedding Module that encodes geometric and structural properties of any skeleton into a shared token space, enabling seamless fusion with textual semantics. Given a text prompt and a target skeleton, our method generates temporally coherent, physically plausible, and semantically aligned motions, and further enables cross-species motion style transfer.
Uni-MoE-2.0-Omni: Scaling Language-Centric Omnimodal Large Model with Advanced MoE, Training and Data
Nov 16, 2025We present Uni-MoE 2.0 from the Lychee family. As a fully open-source omnimodal large model (OLM), it substantially advances Lychee's Uni-MoE series in language-centric multimodal understanding, reasoning, and generating. Based on the Qwen2.5-7B dense architecture, we build Uni-MoE-2.0-Omni from scratch through three core contributions: dynamic-capacity Mixture-of-Experts (MoE) design, a progressive training strategy enhanced with an iterative reinforcement strategy, and a carefully curated multimodal data matching technique. It is capable of omnimodal understanding, as well as generating images, text, and speech. Architecturally, our new MoE framework balances computational efficiency and capability for 10 cross-modal inputs using shared, routed, and null experts, while our Omni-Modality 3D RoPE ensures spatio-temporal cross-modality alignment in the self-attention layer. For training, following cross-modal pretraining, we use a progressive supervised fine-tuning strategy that activates modality-specific experts and is enhanced by balanced data composition and an iterative GSPO-DPO method to stabilise RL training and improve reasoning. Data-wise, the base model, trained on approximately 75B tokens of open-source multimodal data, is equipped with special speech and image generation tokens, allowing it to learn these generative tasks by conditioning its outputs on linguistic cues. Extensive evaluation across 85 benchmarks demonstrates that our model achieves SOTA or highly competitive performance against leading OLMs, surpassing Qwen2.5-Omni (trained with 1.2T tokens) on over 50 of 76 benchmarks. Key strengths include video understanding (+7% avg. of 8), omnimodallity understanding (+7% avg. of 4), and audiovisual reasoning (+4%). It also advances long-form speech processing (reducing WER by 4.2%) and leads in low-level image processing and controllable generation across 5 metrics.
DEPF: A UAV Multispectral Object Detector with Dual-Domain Enhancement and Priority-Guided Mamba Fusion
Sep 09, 2025Multispectral remote sensing object detection is one of the important application of unmanned aerial vehicle (UAV). However, it faces three challenges. Firstly, the low-light remote sensing images reduce the complementarity during multi-modality fusion. Secondly, the local small target modeling is interfered with redundant information in the fusion stage easily. Thirdly, due to the quadratic computational complexity, it is hard to apply the transformer-based methods on the UAV platform. To address these limitations, motivated by Mamba with linear complexity, a UAV multispectral object detector with dual-domain enhancement and priority-guided mamba fusion (DEPF) is proposed. Firstly, to enhance low-light remote sensing images, Dual-Domain Enhancement Module (DDE) is designed, which contains Cross-Scale Wavelet Mamba (CSWM) and Fourier Details Recovery block (FDR). CSWM applies cross-scale mamba scanning for the low-frequency components to enhance the global brightness of images, while FDR constructs spectrum recovery network to enhance the frequency spectra features for recovering the texture-details. Secondly, to enhance local target modeling and reduce the impact of redundant information during fusion, Priority-Guided Mamba Fusion Module (PGMF) is designed. PGMF introduces the concept of priority scanning, which starts from local targets features according to the priority scores obtained from modality difference. Experiments on DroneVehicle dataset and VEDAI dataset reports that, DEPF performs well on object detection, comparing with state-of-the-art methods. Our code is available in the supplementary material.
AdaGAT: Adaptive Guidance Adversarial Training for the Robustness of Deep Neural Networks
Aug 24, 2025



Adversarial distillation (AD) is a knowledge distillation technique that facilitates the transfer of robustness from teacher deep neural network (DNN) models to lightweight target (student) DNN models, enabling the target models to perform better than only training the student model independently. Some previous works focus on using a small, learnable teacher (guide) model to improve the robustness of a student model. Since a learnable guide model starts learning from scratch, maintaining its optimal state for effective knowledge transfer during co-training is challenging. Therefore, we propose a novel Adaptive Guidance Adversarial Training (AdaGAT) method. Our method, AdaGAT, dynamically adjusts the training state of the guide model to install robustness to the target model. Specifically, we develop two separate loss functions as part of the AdaGAT method, allowing the guide model to participate more actively in backpropagation to achieve its optimal state. We evaluated our approach via extensive experiments on three datasets: CIFAR-10, CIFAR-100, and TinyImageNet, using the WideResNet-34-10 model as the target model. Our observations reveal that appropriately adjusting the guide model within a certain accuracy range enhances the target model's robustness across various adversarial attacks compared to a variety of baseline models.